호텔 예약 취소의 인과적 배경: 예측 모델을 넘어선 이야기
이 글은 호텔 예약 취소 문제에 대해 예측 모델을 넘어서 인과적 추론을 적용하는 방법을 설명합니다. 특히, 고객이 예약했던 방과 다른 방을 배정받았을 때 예약 취소에 어떤 영향을 미치는지 밝히고자 합니다. 단순히 상관관계를 보는 것을 넘어, 실제 원인과 결과를 파악하기 위해 DoWhy라는 도구를 활용하여 데이터에서 인과 관계를 모델링하고 검증하는 4단계 프로세스를 상세히 다룹니다.
1. 문제 정의 및 데이터 소개 🏨
우리는 고객에게 예약한 방과 다른 방을 배정했을 때 예약 취소에 미치는 영향을 알아보고자 합니다. 이러한 문제를 해결하는 가장 이상적인 방법은 무작위 대조군 연구(Randomized Controlled Trials, RCT), 즉 A/B 테스트와 같은 실험을 진행하는 것이에요. 각 고객을 무작위로 두 그룹 중 하나에 배정하는 거죠. 한 그룹은 예약한 방과 같은 방을 받고, 다른 그룹은 다른 방을 받는 식으로요.
하지만 현실에서는 이런 실험을 진행하기 어려운 경우가 많아요. 예를 들어, 호텔이 고객들에게 무작위로 다른 방을 배정한다는 사실이 알려지면 호텔의 평판이 나빠질 수 있겠죠? 📉 게다가 실험 비용도 만만치 않을 수 있습니다.
"무작위 대조군 연구(RCT)는 프로그램이나 정책 개입을 받는 모집단을 적격 모집단에서 무작위로 선택하고, 대조군 또한 동일한 적격 모집단에서 무작위로 선택하는 실험적 형태의 영향 평가입니다." – UNICEF
따라서 저자는 과거에 수집된 관측 데이터만을 가지고도 이러한 질문에 답할 수 있는지에 주목합니다.
1.1. 데이터셋 설명
이 분석에 사용된 데이터셋은 포르투갈의 실제 호텔(도시 호텔과 리조트 호텔)에서 수집된 예약 정보입니다. 이 데이터에는 예약 시점, 숙박 기간, 성인/어린이/유아 수, 사용 가능한 주차 공간 수 등 다양한 정보가 포함되어 있어요. 모든 개인 식별 정보는 삭제되었답니다. 이 데이터는 Antonio et al. (2019)의 논문 "Hotel Booking Demand Datasets"에서 가져왔으며, 더 자세한 내용은 여기서 확인할 수 있습니다.
참고로, 이 데이터셋으로 예약 취소 여부를 예측하는 예측 모델을 구축하는 데 관심이 있다면, 저자가 이전에 만든 노트북을 참고해 보세요! 해당 노트북은 주로 탐색적 데이터 분석(EDA)과 모델 구축에 중점을 두고 있습니다.
2. 특성 공학 및 전처리 🛠️
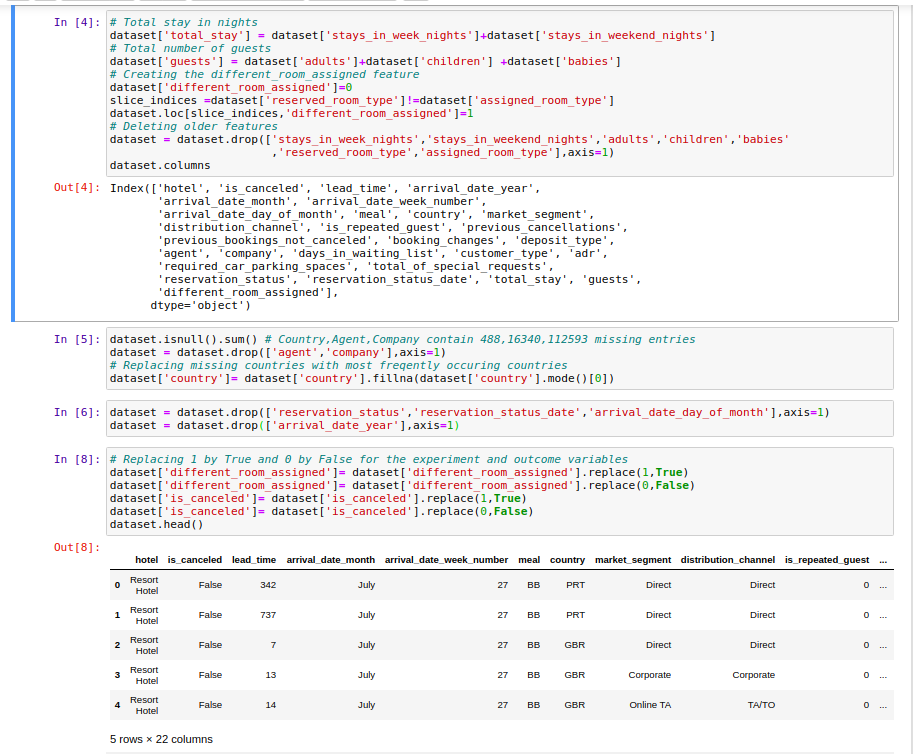
데이터를 분석하기 전에 몇 가지 새로운 특성들을 만들고 전처리를 진행하여 데이터셋의 차원(dimensionality)을 줄이고 의미 있는 정보를 추출했습니다.
다음과 같은 새로운 특성들이 생성되었습니다:
- 총 숙박 일수 (Total Stay) =
주말 숙박 일수 (stays_in_weekend_nights)+주중 숙박 일수 (stays_in_week_nights) - 총 투숙객 수 (Guests) =
성인 (adults)+어린이 (children)+유아 (babies) - 다른 방 배정 여부 (Different_room_assigned) =
예약된 방 유형 (reserved_room_type)과배정된 방 유형 (assigned_room_type)이 다르면 1, 같으면 0.
3. 기대 빈도 계산 및 혼란 변수 탐색 🤔
예약 취소 횟수와 다른 방이 배정된 횟수가 매우 불균형하기 때문에, 우리는 기대 빈도(expected counts)를 계산해 보았습니다.

처음에 계산한 기대 빈도는 약 50%로 나왔는데, 이는 두 변수(취소 여부와 다른 방 배정 여부)가 무작위로 같은 값을 가질 확률을 의미합니다. 통계적으로 이 단계에서는 확실한 결론을 내릴 수 없었어요.
그래서 예약 변경 횟수 (Booking Changes)를 고려하여 기대 빈도를 다시 계산해 보았습니다.
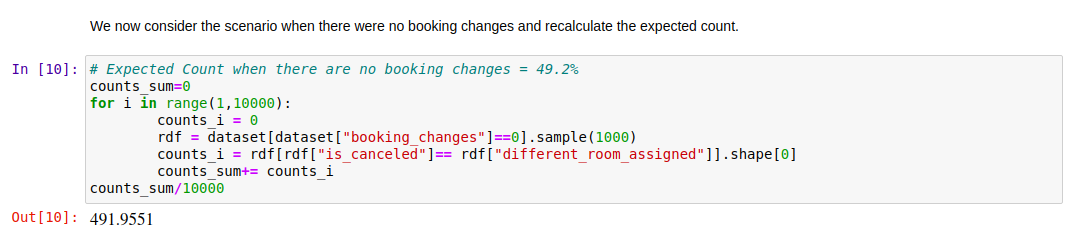
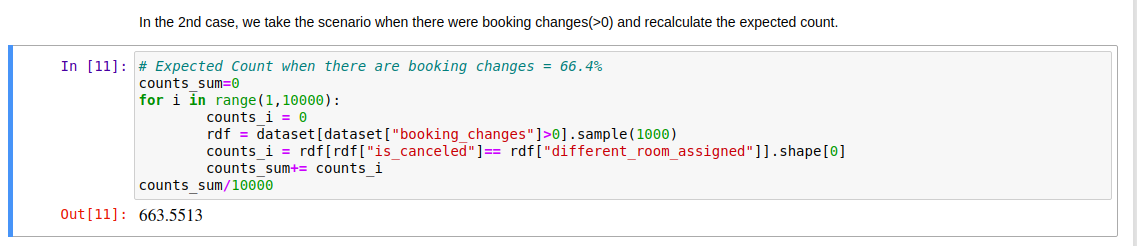
예약 변경 횟수가 0이 아닌 경우에 확실히 변화가 나타나는 것을 볼 수 있었어요. 이는 예약 변경 횟수 (Booking Changes)가 혼란 변수(confounding variable)일 가능성이 있음을 시사합니다.
하지만 예약 변경 횟수만 유일한 혼란 변수일까요? 만약 데이터셋에 정보가 없는 관측되지 않은 혼란 변수(unobserved confounders)가 있다면 어떨까요? 우리는 여전히 같은 주장을 할 수 있을까요? 여기서 DoWhy라는 도구가 등장합니다! 🛡️
4. DoWhy를 이용한 인과 추론 과정 💡
DoWhy는 인과 추론에 필요한 가정에 초점을 맞추고, 매칭(matching)이나 도구 변수(IV)와 같은 추정 방법들을 제공합니다. 이를 통해 사용자는 인과 그래프 모델(Causal Graphical Models)을 사용하여 가정들을 명시적으로 식별하는 데 더 집중할 수 있습니다.
DoWhy의 주요 특징은 다음과 같습니다:
- 입력: 관측 데이터와 인과 그래프. 인과 그래프에는 처리 변수(treatment variable), 공변량(covariates), 결과 변수(outcome)가 명확하게 지정되어야 합니다.
- 출력: 원하는 변수 간의 인과 효과 및 사다리 인과론(Ladder of Causation)의 가장 높은 단계인 "만약 ~라면 어떨까(What-if)" 분석.
DoWhy를 이용한 인과 추론은 크게 4단계로 진행됩니다.
4.1. 1단계: 목표 설정 및 문제 공식화 🎯
우리의 목표는 고객에게 예약한 방과 다른 방을 배정했을 때 예약 취소에 어떤 영향을 미치는지 추정하는 것입니다. 앞서 언급했듯이, 무작위 대조군 연구(RCT)가 이상적이지만, 현실에서는 호텔의 평판 문제나 비윤리적인 상황(예: 6인 가족에게 2인실 배정) 때문에 실행 불가능하거나 비용이 많이 들 수 있습니다.
"우리는 처리(Treatment)가 결과(Outcome)의 원인이라고 말합니다. 이는 처리를 변경하면 다른 모든 것을 일정하게 유지했을 때 결과에 변화가 생긴다는 것을 의미합니다. 인과 효과는 처리의 단위 변화에 따라 결과가 변경되는 크기입니다."
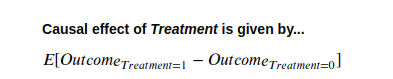
4.2. 2단계: 인과 모델 생성 🌳
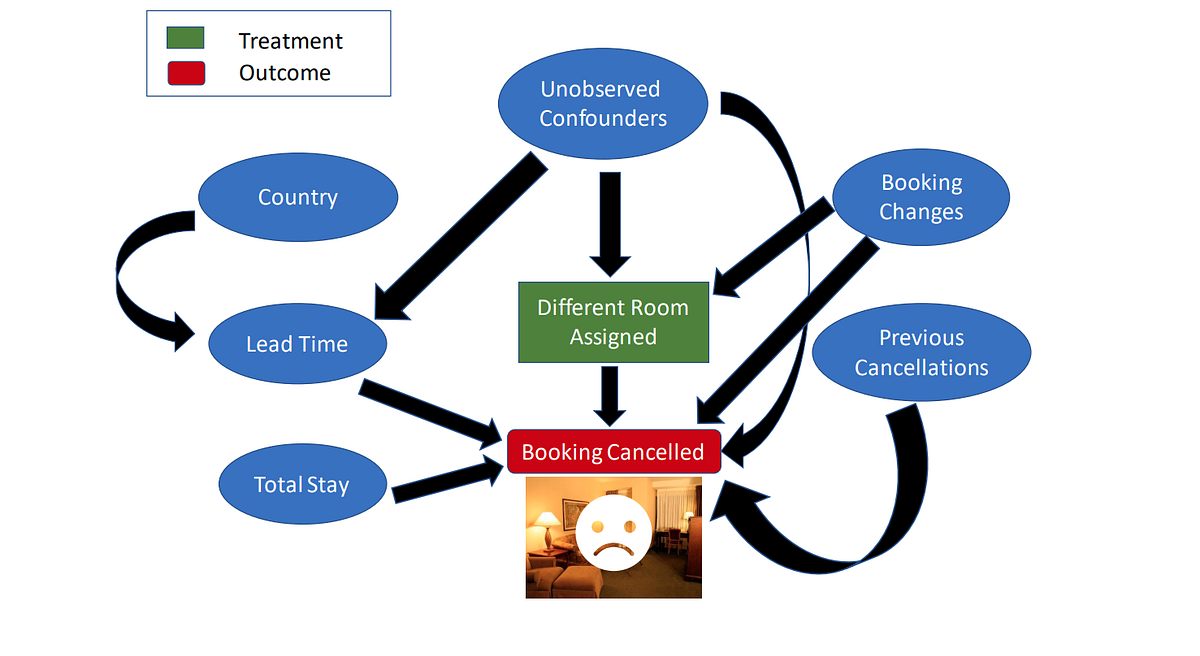
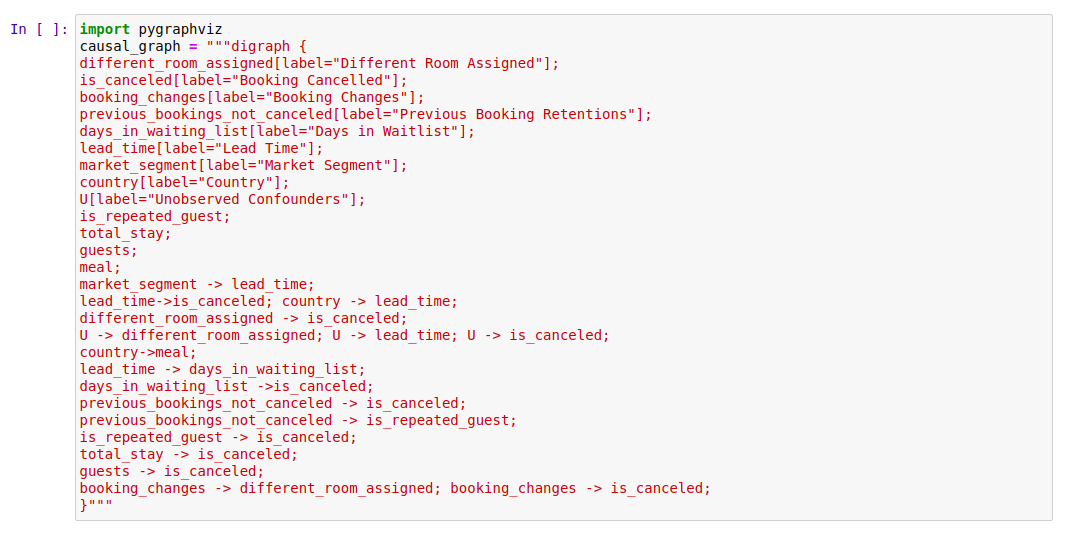
이 단계에서는 예측 모델링 문제에 대한 사전 지식을 인과 그래프(Causal Graph)로 표현합니다. 처음부터 완벽한 그래프를 그릴 필요는 없으며, 부분적인 그래프만으로도 DoWhy가 나머지를 파악할 수 있어요. 저자가 고려한 인과 모델은 Fig-2에 나타나 있습니다.
다음은 저자가 인과 다이어그램으로 변환한 가정들입니다:
- 시장 부문(Market Segment): "TA"(여행사)와 "TO"(여행사 운영자)로 나뉘며, 리드 타임(Lead Time)(예약부터 도착까지의 일수)에 영향을 미칩니다.
- 국가(Country): 개인이 일찍 예약하는지(즉, 더 긴 리드 타임)와 선호하는 식사 유형(Meal)에 영향을 미칠 수 있습니다.
- 리드 타임(Lead Time): 대기 목록 일수(Days in Waitlist)에 영향을 미치고(늦게 예약할수록 예약 찾을 가능성 낮음), 길어질수록 취소로 이어질 수 있습니다.
- 대기 목록 일수, 총 숙박 일수, 투숙객 수: 예약이 취소될지 유지될지에 영향을 줄 수 있습니다.
- 이전 예약 유지 횟수(Previous Booking Retentions): 고객이 반복 투숙객(Repeated Guest)인지 여부에 영향을 미치며, 이 두 변수 모두 예약 취소 여부에 영향을 줍니다. (예: 과거 5번의 예약을 유지한 고객은 이번에도 유지할 가능성이 높고, 이전에 예약을 취소한 고객은 다시 취소할 가능성이 높음).
- 예약 변경 횟수(Booking Changes): 고객에게 다른 방이 배정될지 여부에 영향을 미치며, 이는 또한 취소로 이어질 수 있습니다.
- 관측되지 않은 혼란 변수(Unobserved Confounders): 예약 변경 횟수만이 처리와 결과에 영향을 미치는 유일한 혼란 변수일 가능성은 낮으므로, 데이터에 없는 관측되지 않은 혼란 변수가 존재할 수 있다고 가정합니다.
여기서 처리(Treatment)는 고객이 예약 시 선택한 것과 같은 유형의 방을 배정하는 것이고, 결과(Outcome)는 예약이 취소되었는지 여부입니다. 공통 원인(Common Causes)은 우리의 인과적 가정에 따라 결과와 처리 모두에 인과적으로 영향을 미치는 변수를 나타냅니다. 우리의 가정에 따르면, 이 기준을 만족하는 두 변수는 예약 변경 횟수와 관측되지 않은 혼란 변수입니다.

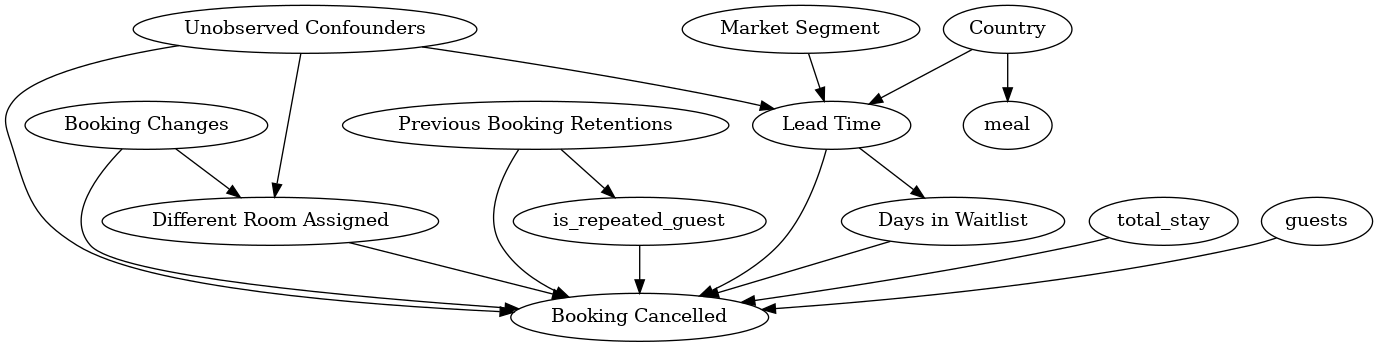
Fig-2: 간단한 그래픽 모델로 명시된 인과적 가정.
저자는 직관과 가정에 따라 Fig-3와 같이 더 상세한 인과 다이어그램을 고려할 수도 있다고 덧붙였습니다.
4.3. 3단계: 인과 효과 식별 🔍
이 단계에서는 인과 그래프의 속성을 사용하여 추정할 인과 효과를 식별합니다.
"처리를 변경하면 결과에 변화가 생기며, 다른 모든 것을 일정하게 유지했을 때 처리가 결과의 원인이라고 말합니다."
"다른 모든 것을 일정하게 유지"하는 것은 반사실적(Counterfactual) 세계를 상상함으로써 이해할 수 있습니다. 이 세계에서는 처리가 도입된 시점까지 모든 것이 동일했지만, '실제' 세계에서는 처리가 제공되었고, '반사실적' 세계에서는 제공되지 않았습니다. 따라서 우리가 관찰하는 결과의 어떤 변화든 오로지 처리 때문이라고 볼 수 있습니다.

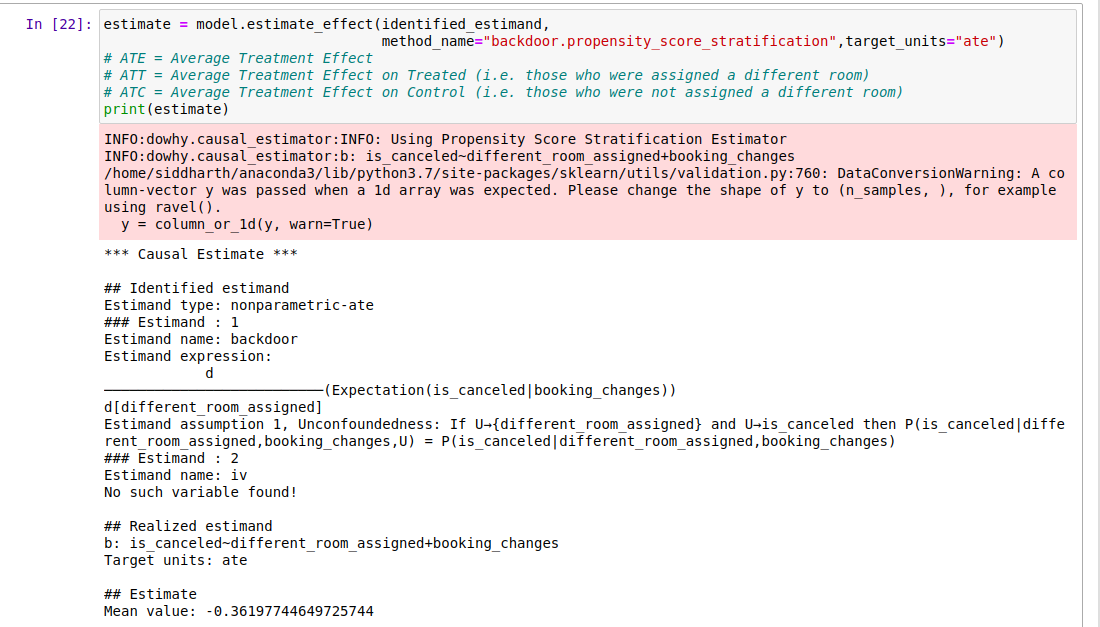
4.4. 4단계: 식별된 인과 효과 추정 📊
인과 효과는 처리의 단위 변화에 따라 결과가 변하는 크기입니다. 추정은 통계적 절차이기 때문에 다른 단계보다 비교적 간단합니다. DoWhy는 식별된 인과 추정치를 계산하는 데 사용할 수 있는 여러 방법을 제공합니다.
이 예시에서는 성향 점수 층화 추정량(Propensity Score Stratification Estimator)이 사용되었습니다. 성향 점수는 관측치가 처리될 경향을 측정하는 지표로 생각할 수 있으며, 데이터에서 추정되거나 모델링되어야 합니다. 이 점수들은 로지스틱 회귀나 랜덤 포레스트와 같은 머신러닝 분류기를 훈련시켜 공변량(결과 변수와 처리 변수를 제외한 모든 변수)이 주어졌을 때 처리 변수를 예측함으로써 계산됩니다. 층화는 공변량 분포가 유사한(다양한 유형의 규범을 사용하여 측정된 유사성) 짝을 이루는 하위 모집단을 식별하는 기술입니다.
이러한 방법 및 기술에 대한 적절한 설명은 DoWhy 개발자들이 KDD'18에서 제공한 튜토리얼을 참고해 보세요.
4.5. 5단계: 얻은 결과 반증 (검증) 📝
인과적 부분은 데이터에서 오는 것이 아니라, 원인을 식별(2단계)하고 추정(3단계)하는 데 사용된 가정(1단계)에서 비롯됩니다. 데이터는 단순히 통계적 추정에 사용될 뿐이죠.
따라서 우리의 가정을 확인하고 그 타당성을 여러 가지 방법으로 검증하는 것이 매우 중요합니다. DoWhy는 가정의 유효성을 테스트하는 데 사용할 수 있는 여러 강건성 검사(Robustness Checks)를 제공합니다:
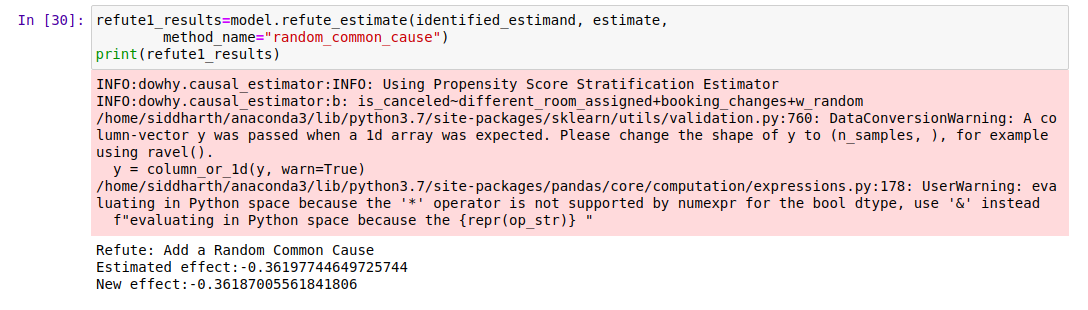
-
무작위 공통 원인 (Random Common Cause): 무작위로 선택된 공변량을 데이터에 추가하고 분석을 다시 실행하여 인과 추정치가 변경되는지 확인합니다. 원래 가정이 정확했다면 인과 추정치에 큰 변화가 없어야 합니다.
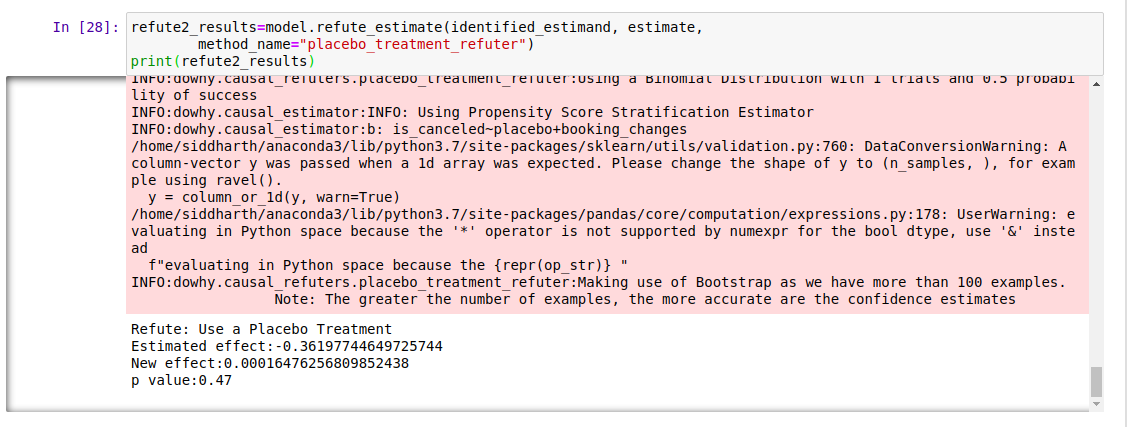
-
위약 처리 반증 (Placebo Treatment Refuter): 임의의 공변량을 처리 변수로 지정하고 분석을 다시 실행합니다. 가정이 정확했다면 새로 발견된 추정치는 0으로 수렴해야 합니다.
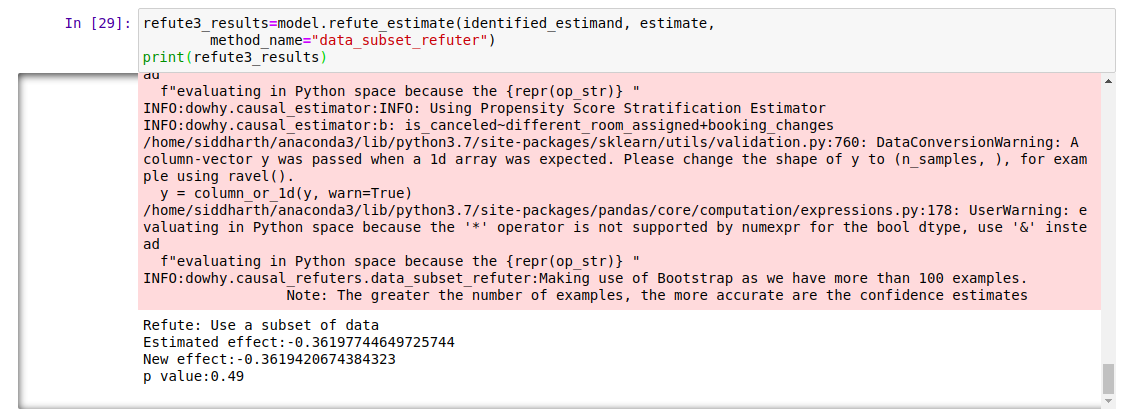
-
데이터 하위 집합 반증 (Data Subset Refuter): 데이터의 하위 집합을 생성하고(교차 검증과 유사), 인과 추정치가 하위 집합마다 달라지는지 확인합니다. 가정이 정확했다면 큰 변화가 없어야 합니다.
다중 강건성 검사를 통해 우리의 인과적 가정이 실제로 정확했음을 검증했습니다!
이 분석 결과, 평균적으로 고객이 예약 시 선택한 것과 같은 방을 배정받았을 때 호텔 예약이 취소될 확률이 다른 방을 배정받았을 때보다 약 36% 감소하는 것을 알 수 있습니다.
따라서 호텔 직원들이 난처한 상황에서 고객에게 다른 방을 배정해야 할 때, 그들의 행동이 예약 취소에 얼마나 큰 영향을 미칠지 알게 된 것이죠! 🏨🚫
5. 보너스 팁: 인과 추론 베스트 프랙티스 ✨
관측 데이터를 가지고 인과 추론을 수행할 때 따를 수 있는 몇 가지 모범 사례가 있습니다:
- 모델, 식별, 추정, 반증의 네 단계를 반드시 따르세요.
- 간단함을 목표로 하세요. 분석이 너무 복잡하다면 대부분 잘못되었을 가능성이 높습니다! 😵💫
- 서로 다른 가정을 가진 최소 2가지 방법을 시도해 보세요. 두 방법이 모두 일치한다면 추정치에 대한 신뢰도가 더 높아집니다.
마무리하며
이 글은 호텔 예약 취소 문제에 대해 단순한 예측을 넘어 인과 관계를 탐구하는 중요한 여정을 보여주었습니다. 특히 DoWhy 프레임워크를 활용하여 가정-식별-추정-반증의 체계적인 과정을 거침으로써, 고객에게 예약과 다른 방을 배정하는 것이 예약 취소율을 약 36% 증가시킨다는 중요한 인과적 결론을 도출했습니다. 이는 호텔 운영자가 의사 결정을 내릴 때 예측 모델만으로는 알 수 없었던 실질적인 행동의 영향을 이해하는 데 큰 도움을 줄 것입니다. 인과 추론은 복잡한 현실 문제 속에서 더 현명한 결정을 내릴 수 있도록 돕는 강력한 도구임을 다시 한번 확인할 수 있었네요! 🚀