
메타(Meta)의 AI 추론 효율 혁신: 반복적 사고를 행동 매뉴얼로 바꾸다
메타(Meta) 연구진이 대형 언어모델(LLM)에서 발생하는 비효율적인 반복적 추론 현상을 파헤치고, 이를 해결할 새로운 방식인 "행동 매뉴얼" 개념을 선보였습니다. 이 요약에서는 연구의 주요 흐름을 시간순으로 알기 쉽게 정리하고, 중요한 인용과 그림, 핵심 논점을 놓치지 않고 풀어 설명합니다. 복잡한 AI 내부를 이해하고 싶은 분이라면, 꼭 한번 읽어볼 만한 내용입니다!
1. AI가 빠지는 비효율의 덫: 같은 내용 반복하기
메타의 연구진은 대형 언어모델(LLM) 이 복잡한 문제를 풀 때 동일한 근본적인 작업(예: 분수 덧셈에서 공통분모 찾기)을 여러 번, 혹은 쓸데없이 길게 반복한다는 문제를 발견했습니다. 이로 인해 AI의 추론 과정이 불필요하게 길어지고 비효율이 커졌던 거죠.
"대형 언어모델은 긴 사고의 사슬을 따라갈 때, 같은 일을 반복해서 처리합니다. 예를 들어 서로 다른 분모를 가진 분수를 더할 때, 모델이 공통분모를 찾는 과정을 다시 설명하곤 하죠."
이 문제에 대한 더 자세한 설명이 그림으로도 제공되어 있습니다.

2. '행동' 개념 도입: 사고 단계를 작은 단위로 저장
메타 연구진이 제안한 핵심은 모델의 추론 과정을 "행동(behavior)"이라는 단위로 쪼개어 명확히 저장하는 것입니다. 행동은 특정 문제를 푸는 반복 가능한 절차(예: 포함-배제 원리 적용, 문장 수식을 수식으로 전환 등)에 짧은 이름과 설명을 붙여 행동 매뉴얼(procedural memory handbook)에 모읍니다.
- 이런 행동 매뉴얼은 RAG(Retrieval-Augmented Generation, 정보 검색 기반 생성 모델)이 사실을 저장하듯, '절차'를 저장합니다. 그래서 AI가 뭔가를 할 때 새로운 추론보다는 미리 정의된 "행동"을 참고할 수 있죠.
3. 행동 추출과 재활용: AI가 스스로 배우고 되새김질하다
연구진은 행동 큐레이션 파이프라인이라는 절차를 고안했습니다.
- 문제 풀기: 모델(LLM A)에게 수학 문제를 줍니다.
- 해결 및 반성: 모델이 풀어보면서 자신이 쓴 논리적 과정을 돌아봅니다.
- 행동 추출: 그 과정 중 재활용이 가능할 만한 중요한 단계를 '행동'으로 추출합니다.
"여기서 반복되거나 본질적인 단계를 무엇으로 정리할 수 있지?"
이렇게 모인 행동들은 그림처럼 각 단계별로 정리됩니다.
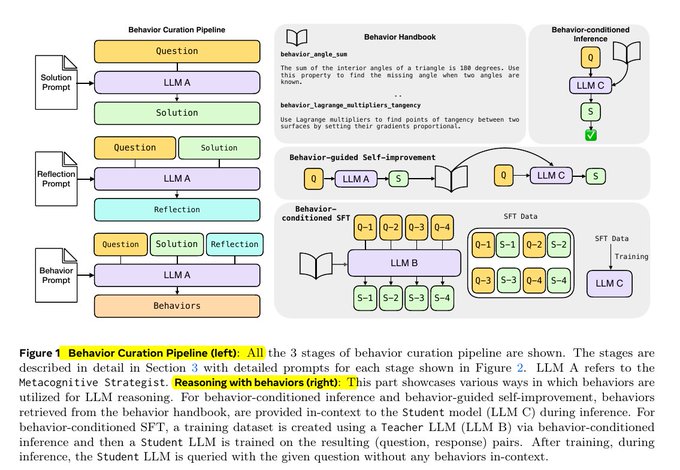
4. 실전 적용: '학생' AI는 행동 매뉴얼을 참고해 답을 낸다
테스트할 때 AI에게 문제와 함께 연관 행동들을 같이 제공합니다. 그러면 AI는 논리를 펼칠 때, 꼭 행동을 참조해서 대답하도록 지시받습니다.
- 행동 검색 방법:
- MATH 데이터셋에서는 주제별 레이블로,
- AIME(수학 올림피아드 문제)의 경우는 BGE-M3 임베딩 및 FAISS 인덱스로 주제와 맞는 40개의 행동을 불러옵니다.
그 결과 행동 매뉴얼을 참고한 답변은
- 사고 단계가 짧아지고
- 정확도도 기존보다 동일하거나 더 높아지는 효과를 가져왔습니다.

5. 자기주도적 개선: 추론 과정의 지속적 업그레이드
재미있는 점은, 같은 AI 모델이 스스로 추출한 행동들을 다음 번 풀이에서 참고하게 하고, 그 결과를 기존의 문제풀이 개선 방식과 비교했다는 점입니다.
- Critique-and-revise(비판·수정 중심 방식)보다 행동 방식이 대부분의 경우 더 좋은 결과를 보였습니다.
- 토큰(코딩 단위)이 많아질수록 정확도 차이가 더 크게 벌어졌고, 10%p 정도 향상되는 수치도 보였죠.
"토큰을 많이 쓸수록 행동 기반 풀이가 기존 방식보다 10% 정도 더 정확해집니다. 핵심은 정확도의 큰 점프!"
6. 행동 매뉴얼(Handbook) 관리와 검색
연구팀은 문제와 행동을 임베딩(벡터화)하여 FAISS(빠른 유사도 검색 라이브러리)에 저장합니다. 그러면 핸드북이 점점 커져도, 입력된 질문에 맞춰 가장 관련 있는 행동만 빠르게 몇 개 뽑아서 참고하게 설계했어요. 덕분에 AI의 문맥 기억 부담도 줄고, 고민할 범위도 핵심만 좁혀집니다.
7. 효율성과 비용 분석: 길어지는 입력, 짧아지는 출력 = 비용 절감
행동 매뉴얼 방식은 입력에 약간 더 많은 토큰을 쓰지만, 출력 토큰을 크게 줄입니다. 대부분의 대형 언어모델 시스템에서 출력 생성이 훨씬 비싼 작업이기 때문에, 전체 비용은 오히려 줄고 지연(latency)도 개선됩니다.
- 행동 임베딩은 미리 계산해 둘 수 있고, 많은 API는 입력보다 출력에 더 비싼 요금을 부과하니 경제적입니다.

8. 업계 반응 및 확장 아이디어
이 연구에 대한 반응도 뜨거웠습니다. 핵심을 찌르는 제안들도 있었죠.
"최종 해답을 얻기까지 필요한 토큰 수마다 마이너스 보상을 주고, 답을 내면 플러스 보상을 주는 RL(강화학습)도 적용해야 해요. 그게 더 빠르게(효율적으로) 학습하는 길입니다."
하지만 비판도 있었습니다.
"이런 연구는 Meta 같은 랩에서만 나올 수 있죠. (혀를 차는 듯한 논조)"
긍정적 분석도 이어졌습니다.
"행동과 신호의 조합이 즉흥적인 추론보다 더 우위네요. 진짜 AGI(범용 인공지능)의 핵심은 이렇게 기억, 습관, 루틴이 모여 점화되는 데 있다 생각해요."
결론
메타의 이번 연구는 AI의 복잡한 사고가 비효율적으로 반복될 때, 그 내부 절차를 '행동'이라는 단위로 정리하고 재활용함으로써 정확도·속도·비용 모두 챙길 수 있다는 새로운 방법을 제시합니다. 이 방식은 앞으로 더 효율적이고 똑똑한 AI를 만드는 기반이 될 가능성이 크며, 응용과 확장 가능성도 매우 높다는 점에서 주목받고 있습니다. 💡