넷플릭스는 하루 1억 4천만 시간의 시청 데이터를 어떻게 저장할까?
넷플릭스는 매일 엄청난 양의 시청 데이터를 안정적이면서도 빠르게 저장·관리해야 합니다. 초창기에는 Cassandra 기반의 단순한 구조로 시작했지만, 사용자와 사용패턴의 폭발적인 성장으로 점차 한계에 부딪혔고, 이에 따라 데이터 구조와 저장 방식을 여러 번 혁신적으로 개선했습니다. 데이터 유형 분리, 캐싱 최적화, 시간별 데이터 관리 등을 통해 넷플릭스는 글로벌 서비스에도 끊김 없는 맞춤형 경험을 제공할 수 있게 되었습니다.
1. 넷플릭스는 왜 복잡한 데이터 저장이 필요하게 되었나?
매일 수백만 명이 넷플릭스를 이용해 영화와 TV 프로그램을 시청하면서 엄청난 시청 기록(타임시리즈 데이터)이 생성됩니다.
예를 들어 각 사용자가
- "무엇을, 언제 시청했는지"
- "어디서 일시정지하거나 중단했는지"
- "다시 돌아와 이어봤는지"
등의 행동을 할 때마다, 새로운 기록이 쌓입니다.
이러한 데이터는
- 이어보기(Resume Watching)
- 개인화 추천
- 콘텐츠 제안
등 다양한 기능의 핵심 기반이 됩니다.
하지만 사용자가 많아질수록 시청 기록은 계속 늘어나고, 콘텐츠와 기능이 확장될수록 기록의 양도 폭발적으로 증가했습니다.
"만약 이 데이터를 제대로 관리하지 못하면 시청 기록이 느리게 로드되거나, 맞춤 추천이 엉망이 되거나, 심지어 이어보던 곳을 잃어버릴 수도 있습니다."
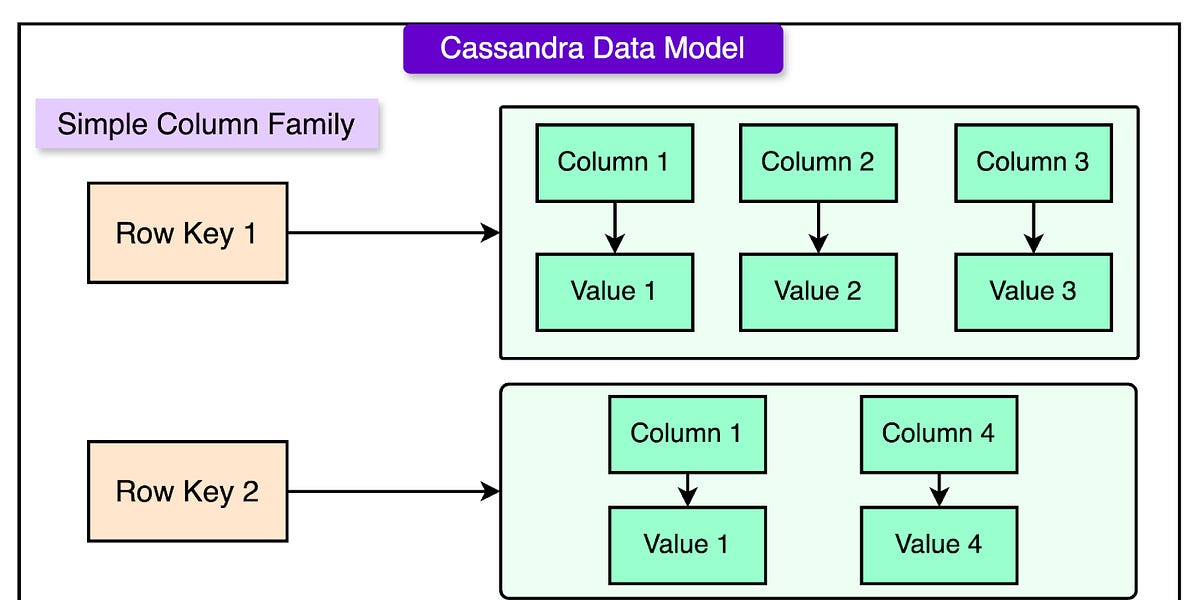
2. 처음엔 Cassandra로 출발! 넷플릭스의 기본 데이터 모델
대량의 시청 데이터를 관리하기 위해 넷플릭스는 **Apache Cassandra®**를 선택했습니다.
- 유연한 구조: 사용자마다 시청 기록이 늘어나더라도 성능 저하 없이 관리 가능
- 쓰기 중심: 읽기보다 새로운 데이터 기록(쓰기)이 압도적으로 많음. Cassandra는 이런 환경에 적합
- 가용성 위주: 강한 일관성보다 '언제나 사용 가능'에 집중
아래 그림처럼,
각 사용자의 시청 기록은 CustomerId를 기준으로 나눠 저장되었습니다.

데이터 분산(수평 파티셔닝)으로 서버 부하도 분산하며, 사용자가 시청을 시작하면 새 컬럼이 추가되고, 일시중지/재생 시 해당 컬럼의 정보가 갱신됩니다.
이렇게 쌓인 데이터를 조회하는 초기 방식은
- 전체 시청 기록 일괄 조회(짧은 기록일 때만 빠름)
- 특정 기간의 기록만 조회(성능은 데이터 양에 따라 다름)
- 페이징(분할 조회, 대기 시간은 늘어남)
3. 성장의 벽: 캐싱과 데이터 분리 전략 도입
사용자가 늘고 데이터가 쌓일수록 문제가 나타났습니다.
- SSTable 파일 급증: Cassandra는 데이터를 SSTable이라는 파일에 저장하는데, 이게 너무 많아져 읽을 때 매번 너무 많은 파일을 찾아야 했습니다.
- 컴팩션 비용 증가: 파일을 합치고 정리하는 작업도 커서 속도와 서버 부담이 늘었습니다.
이에 넷플릭스는 EVCache라는 메모리 캐싱 계층을 추가했습니다.
"이제 모든 데이터를 데이터베이스에서 읽지 않고, 압축해서 캐시에 저장해 필요할 때 꺼내 씁니다."
그러나 모든 시청 기록을 동일하게 관리하면, 최근 기록 위주로 자주 접근되는데도 불필요한 오래된 데이터를 계속 읽고 쓰는 비효율이 생겼죠.
그래서 시청 기록을 두 종류로 분리합니다:
- Live Viewing History(LiveVH): 최근, 자주 접근되는 기록(비압축, 빠른 처리)
- Compressed Viewing History(CompressedVH): 거의 접근하지 않는 오래된 기록(압축 저장으로 효율적 관리)

LiveVH는 빈번한 업데이트와 빠른 접근, CompressedVH는 저장 공간과 처리 효율에 초점을 맞췄습니다.
4. 데이터 폭증과 기능 고도화: 저장 아키텍처의 대전환
글로벌 진출(130여 개국, 20개 언어 지원)과 UI 미리보기(Preview) 도입으로 데이터 규모가 기하급수적으로 커졌습니다.
여기서 나타난 새로운 문제:
- 미리보기/전체재생/언어설정 등 서로 다른 성격의 데이터가 모두 똑같이 취급
- 언어설정은 여러 기록마다 중복 저장됨(공간 낭비)
- 짧은 미리보기가 전체 데이터 성장의 30%를 차지
- 대부분 최근 기록만 필요한데 항상 전체 기록을 읽음(불필요한 네트워크 비용, 느림)
- 일부 요청이 너무 느려 사용자 경험 저하
"기존 시스템은 이제 확장이 불가능하다. 카산드라를 한계까지 밀어붙였지만, 이제는 구조 자체를 바꿔야 했다."
5. 데이터 유형·시간별 분산 저장으로 진화한 아키텍처
유형별 클러스터 분리
넷플릭스는 시청 기록을 세 가지로 분리해 각각 별도의 데이터베이스 클러스터에 저장했습니다:
- Full Title Plays: 실제 영화·방송 전체 또는 일부 재생 정보(중요 데이터)
- Video Previews: 미리보기 영상(짧고 많이 생성, 중요도는 낮음)
- Language Preferences: 음성/자막 선택 정보(이제는 한 번만 저장)

시점별 클러스터 분리
최근~과거~역사의 3단계로 나눠 최적화했습니다.
- Recent Cluster: 최근(며칠~몇 주) 데이터 빠른 접근
- Past Cluster: 몇 달~몇 년 전 데이터(느리지만 상세)
- Historical Cluster: 여러 해 전 데이터(영향 적으니 압축·요약만 보관)
쿼리 목적에 따라 필요한 곳에서만 데이터를 읽으니,
"과거 기록이나 미리보기가 전체 시스템의 발목을 잡지 않게 됐다."
6. 지능형 데이터 이동, 캐싱 혁신
저장 공간 최적화
- 미리보기가 너무 짧을 경우 아예 저장하지 않음
- 언어설정도 한번만 저장, 변경사항만 기록('델타' 방식)
- 일정 기간 지난 쓸모없는 데이터는 자동 만료(삭제)
- 최근 기록은 비압축, 오래된 기록은 압축
쿼리 성능 혁신
- 최근 데이터 요청엔 빠른 Recent Cluster만 조회
- 과거 데이터는 여러 클러스터를 병렬로 읽어서 시간 단축
- 사용자 전체 기록 요청 시 각 클러스터에서 합쳐서 빠르게 반환
데이터 자동 이동(티어드 스토리지)
- 일정 기간이 지나면 과거 클러스터로 자동 이동
- 더 오래된 것은 요약·압축해 Historical Cluster로 보관

EVCache도 진화
클러스터 구조를 반영한 캐싱 구조와
요약 정보 캐시까지 더해져, 요청의 99%가 메모리에서 즉시 해결됩니다.

마무리
넷플릭스의 시청 기록 저장 시스템은 처음엔 단순했지만, 풍부한 사용자 경험과 글로벌 확장을 위해 여러 번 진화했습니다.
- 데이터 분리, 압축, 캐싱, 지능적 이동을 통해
속도, 비용, 안정성 모두에서 생태계를 확장할 수 있었죠.
"이 혁신 덕분에 전 세계 수억 명에게 맞춤형 추천과 이어보기를 끊김 없이 제공할 수 있습니다."
넷플릭스의 기술적 도전과 해법은 초대형 서비스 플랫폼이 왜 '똑똑한 데이터 저장'이 필요한지 보여주는 대표 사례입니다. 🍿