
디지털 광고의 황금기와 LLM 수익성 논쟁
최신 연구와 실무 사례를 통해, 대규모 언어 모델(LLM)이 디지털 광고 최적화에 가져오는 혁신과 그 경제적 효과를 살펴봅니다. 또한, LLM 개발사의 수익성과 경쟁 구도를 둘러싼 업계 주요 인사들의 시각도 함께 정리합니다.
대규모 AI/LLM의 발전이 가져올 실제 시장 변화와 미래 가능성을 쉽고 생생하게 전달합니다.
1. Meta의 LLM 기반 광고 혁신: 텍스트 생성 도구의 실제 효과
Meta(구 페이스북)는 최근 LLM을 기반으로 광고 문구를 자동 생성·개선하는 "Text Generation" 기능을 Ads Manager(광고 관리자)에 도입했습니다.
광고주가 직접 작성한 문구를 입력하면, LLM이 다양한 변형 문구를 즉시 제안해주어, 작업 속도와 아이디어 다양성이 획기적으로 향상됩니다. 광고주는 이중 원하는 문구를 편집하거나 그대로 쓸 수 있어 완전한 주도권을 유지합니다.
"광고주가 자신의 문구를 입력하면, LLM은 그 아이디어를 바탕으로 여러 버전을 제안합니다. 일종의 브레인스토밍 파트너 역할이죠."
실제로 아래 그림은 이 기능의 인터페이스를 보여줍니다.
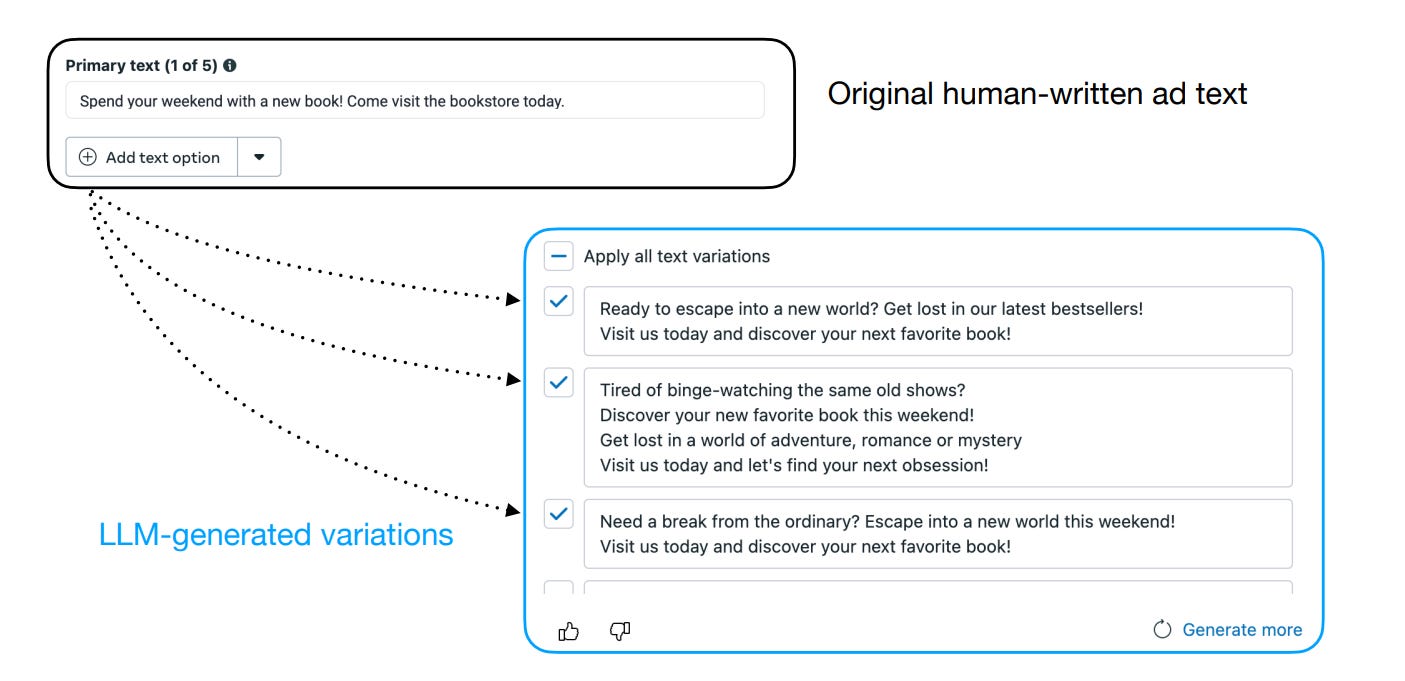
Meta 연구진의 RLPF 논문에서 발췌(2024)
2. RLPF 방식: 광고 텍스트 성능의 혁신적인 개선
이번 연구의 핵심은 성능 피드백 기반 강화학습(RLPF, Reinforcement Learning with Performance Feedback)과 'AdLlama'라는 LLM을 활용한 실험이었습니다.
일반 LLM(흔히 '모방 모델')은 사람의 문장 스타일을 흉내내지만, AdLlama는 실제 광고 성과(즉, 클릭률·CTR)을 극대화하도록 학습되었습니다.
- 먼저, 과거 수억 건의 광고 데이터를 바탕으로 어떤 문구가 더 높은 CTR을 가져왔는지 "쌍 비교" 구조로 학습합니다.
- 이렇게 만들어진 성능 보상 모델(Performance Reward Model)이 다양한 문구를 CTR 관점에서 즉각 평가할 수 있게 되죠.
- 이후, 이 보상 모델의 신호를 바탕으로 원래의 LLM(여기서는 Llama 2 Chat 7B)을 미세조정(fine-tune)합니다.
이 과정을 통해 LLM 스스로 "실제로 더 많이 클릭받는 광고 문구"를 생산해내는 것입니다.
아래 다이어그램은 이러한 '광고 성능 피드백 루프'의 실제 구조를 한눈에 보여줍니다.
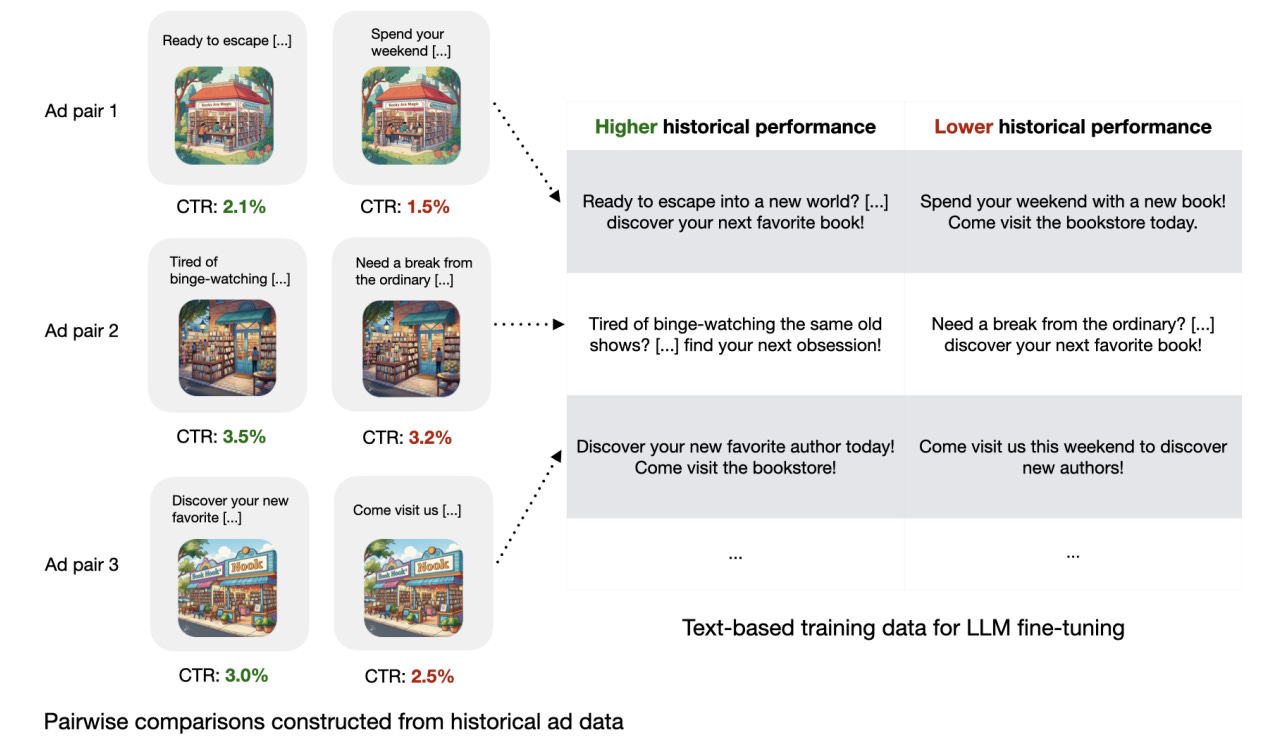
3. 실제 대규모 실험 결과: 눈에 띄는 효율성 향상
2024년 초 Meta는 약 10주간 Facebook에서 대형 A/B 테스트를 진행했습니다.
- 약 3만 5천 명의 광고주,
- 64만여 개의 광고 문구 변화가 생성되는 초대형 실험이었습니다.
▶ 참가자 절반은 기존 모방 LLM(Imitation LLM V2, 대조군), 나머지는 RLPF로 학습된 AdLlama를 사용(실험군)하게 했습니다.
결과는 매우 뚜렷했습니다!
"AdLlama를 쓴 광고주 그룹은 기존 모델 대비 CTR(클릭률)이 6.7%나 상승했어요."
- 무엇보다 "광고 노출 수(=광고의 총 보여진 횟수)는 변화 없고, 광고 자체가 더 경쟁력 있게 클릭을 더 많이 유도했다"는 점이 인상적이었습니다.
- AdLlama를 쓴 광고주들은 생성된 광고 문구 버전(variation)도 18.5% 더 많았습니다. 즉, AI가 내놓은 문구들이 실제 현업에 더 유용하다고 느꼈다는 방증이죠.
Meta CEO인 마크 저커버그도, 최근 실적 발표에서 다음과 같이 강조했습니다.
"내부 팀들이 Llama 4를 활용해 Facebook 알고리즘을 자율적으로 개선하고, 질과 참여도를 높이고 있습니다. 이건 정말 심오한 일입니다."
"슈퍼인텔리전스를 개발하려면 결국 인간을 넘어서는 무언가를 만들어야 하죠. 그러려면 자기 스스로 학습하고 개선하는 법을 배워야 합니다."
"이런 변화는 제품 개발, 회사 운영, 그리고 심지어 사회 전반에도 대단히 광범위한 영향을 줄 것이라고 생각해요."
4. RLPF의 확장성: 광고를 넘는 실전 활용 가능성
이 방식을 채택하면, "실제 사용자들의 피드백(클릭률 등)"로 AI를 직접 튜닝할 수 있게 됩니다.
이 원리는 광고를 넘어서, 언어가 성과로 직접 연결되는 다양한 분야(이메일 마케팅, e-커머스 설명, AI 고객센터, 교육 플랫폼 등)에 적용이 가능합니다.
연구진은 다음과 같이 밝힙니다.
"더 몰입감 있는 광고 콘텐츠 생성 능력은, 신생·경험 부족 광고주(소상공인 등)에도 진입 장벽을 낮춰줍니다. 마케팅 노하우와 자원이 부족해도 광고 효율을 끌어올릴 수 있죠."
"…RLPF의 원칙은 성과 지표가 존재하는 다른 영역에도 적용 가능합니다. 기업은 원하는 성과에 딱 맞는 형태로 LLM을 미세조정할 수 있어요. 예를 들어 퍼스널라이즈된 이메일, e-커머스 제품 설명문 자동 생성, 반복적 상호작용이 필요한 AI 고객상담원까지, 모두 실제 성과 데이터를 토대로 최적화가 가능합니다. 온라인 학습 플랫폼의 경우에도 학생들의 시험 점수나 참여 지표로 AI를 튜닝해서 더 효과적인 맞춤형 학습자료를 만들 수 있죠."
5. LLM 수익 구조: 끝없는 투자, 언제부터 이익일까?
디지털 광고가 실제 수익 창출에 이렇게 혁신적 기여를 한다면, LLM을 개발하는 회사들도 과연 돈을 벌 수 있을까?
Stripe 공동 창업자 존 콜리슨과 Anthropic 공동 창업자 다리오 아모데이의 대담(2024)이 흥미로운 시각을 던집니다.
아모데이는 "모델 단위의 손익 계산" 개념을 소개합니다.
- 예를 들어 2023년, 1억 달러를 들여 모델을 훈련해 2024년에 2억 달러 수익을 내면, 그 '2023년 모델'은 자체적으로는 이익을 내는 회사와 비슷하다는 논리입니다.
- 그러나 동시에 더 큰 모델을 훈련하는 R&D 지출이 기하급수적으로 늘어나기 때문에, 회사 전체로 보면 손실이 누적되는 현상이 나타납니다.
"2023년 1억 달러 들인 모델이 2억 달러를 벌면 그 모델은 수익성을 보입니다. 하지만 2024년에는 10억 달러를 들여 또다른 모델을 훈련하죠. 이런 일이 반복되면, 회사 전체의 손실은 커지는 것처럼 보입니다."
"이 흐름이 언젠가 모델 성능 한계에 다다르면, 돌연 극적인 수익성이 실현될 수 있습니다. 또는 반대로 기대했던 만큼 성능 향상이 일어나지 않으면 한꺼번에 많은 손실이 남을 수도 있죠."
"중요한 질문은 언제, 그리고 어느 규모에서 '균형'에 다다르는가입니다. 혹은 과잉투자가 일어날까요?"
특정 모델(모델 '코호트')별로는 채산성이 나타나나, 전체 시장 환경에서는 고도의 경쟁 때문에 수익성이 떨어질 수도 있다는 점을 필자는 현실적으로 지적합니다.
예를 들어 칩, 클라우드 인프라 시장은 독점/과점에 가깝지만, LLM 개발 시장(모델 사업자)은 훨씬 더 치열하고 고객 선택지가 빠르게 늘고 있다는 점이 특히 강조됩니다.
6. 모델 차별화 논쟁: LLM의 '개성'이 진짜 무기일까?
Amodei는 LLM이 클라우드 API(예: AWS, GCP)와 달리 각기 다른 '성격(개성)'을 지녀 차별화·탈상품화 위험이 낮다고 주장합니다.
"클라우드 업체는 대체로 비슷하지만, 우리가 만드는 AI 모델은 성향과 특성이 명확히 다르고, 각각 마치 사람과 대화하듯 다릅니다. 같은 방에 비슷한 사람이 10명 있어도, 그 중 한 명이 불필요하게 느껴지지 않는 것처럼요."
"…우리(Anthropic)는 여러 클라우드도 쓰는데, 클라우드 업체가 실제로 훨씬 덜 차별화되어 있습니다."
하지만 저자는, 클라우드 시장처럼 데이터 중력, 계정권한, 네트워킹 등 내재적 '잠금효과(락인)'가 LLM 플랫폼에는 약하다고 지적합니다. 특히, 기업 대상 대형 계약일수록 '모델 개성'의 차별성이 실제 경쟁 우위로 작동할지는 아직 미지수라고 본 것입니다.
7. 마치며
Meta를 비롯한 주요 플랫폼은 LLM 활용으로 광고 효율과 실제 수익을 의미 있게 높이고 있습니다.
"실제 성과 데이터를 활용한 강화학습" 원리는 광고를 넘어 다양한 디지털 콘텐츠, 마케팅, 고객 지원, 심지어 교육까지 영향이 확장될 전망입니다.
다만, LLM 자체의 수익성 구조는 아직 갈 길이 멉니다. 경쟁 심화, 투자 증가, 클라우드와의 차별화 등 해결해야 할 숙제가 많고,
AI가 새로운 경제 논리를 만들어낼지, 아니면 과거와 비슷한 규모의 '수익 한계'로 향할지, 시장의 관심은 여전히 뜨겁습니다. 🚀